 When training a neural network to generate human faces there is typically a stage before training completes where the generated faces can have a horrifying look to them. Often it is the eyes that become most noticeable. Apart from the obvious sense of vision, eyes play an important role in many animals. In dogs, for example, eye contact may be a method to assert dominance. Those pretty spots on butterflies help them avoid being eaten by birds by giving the impression that the butterfly is aware of the bird’s presence, and is in fact looking at them. Horror movies have countless times used eyes as a means to instill terror in the viewer. While distorted eyes in generated human faces add to the uneasiness of the figures, the disfigured form of the overall face also makes a major contribution. In the recent Momo hoax, not only does the fixation of the oversized eyes make Momo hard to look at, but the close-to-human form of the face adds to the uneasiness.
When training a neural network to generate human faces there is typically a stage before training completes where the generated faces can have a horrifying look to them. Often it is the eyes that become most noticeable. Apart from the obvious sense of vision, eyes play an important role in many animals. In dogs, for example, eye contact may be a method to assert dominance. Those pretty spots on butterflies help them avoid being eaten by birds by giving the impression that the butterfly is aware of the bird’s presence, and is in fact looking at them. Horror movies have countless times used eyes as a means to instill terror in the viewer. While distorted eyes in generated human faces add to the uneasiness of the figures, the disfigured form of the overall face also makes a major contribution. In the recent Momo hoax, not only does the fixation of the oversized eyes make Momo hard to look at, but the close-to-human form of the face adds to the uneasiness.
The Uncanny Valley
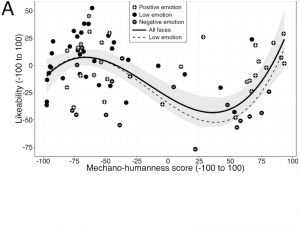
The uncanny valley refers to the discomfort or uneasiness associated with humanoid faces that are not quite perfect. As similarity to a humanoid face increases, an individual will typically feel an increased empathy toward that face, but as the similarity increases even more, there is a point (called the uncanny valley) where discomfort, uneasiness, or disgust might form. Past this valley, as the similarity to a human face becomes perfect, this uneasiness goes away and empathy is restored. One of the most reliable ways of inducing the uncanny valley is by enlarging the eyes of a human face. (Interestingly, while the uncanny valley effect is present in children, those with autism spectrum disorder do not appear to be affected by the uncanny valley (Feng et al., 2018))
There are several theories that attempt to explain the uncanny valley, which include mate selection, where health and fertility of an individual might be represented by the face; mortality salience, where a disfigured face may provide a sign of death; and pathogen avoidance, where defects in the face may indicate disease. Regardless of what is the cause of the uncanny valley, it is something that must be considered in the design of artificial life forms, such as robots, that are meant to look human. Wikipedia provides a more comprehensive list and discussion of these theories.
A.I. Nightmares
It is difficult to measure the contributions of the various factors mentioned previously to the eeriness of faces generated by AI. In many cases, neural networks have become good enough at this task that they can create faces so realistic that it is difficult to distinguish between what is real and what is not (see This Person Does Not Exist). In the video “A.I. Nightmares” we show a series of faces generated by a network trained to convert cute anime faces into human faces. Training on this task did not reach a stable state where realistic human faces could consistently be generated. Instead, while the faces are recognizable as human, they also have a certain level of creepiness to them.
How it was Made
The neural network used to generate the video was a rewrite of a fairly well-known network called MUNIT. MUNIT stands for “Multimodal Unsupervised Image-to-Image Translation.” Put simply, the network can be trained to translate one set of images (such as a set of Anime faces) to look like they belong to a second set of images (such as a set of human faces). MUNIT uses standard components found in other neural network-based image processing tasks, which are composed of a series of filters applied to the pixels of the images. Like the neurons in the visual cortex, these filters process certain features of our visual field, such as lines and edges, gradients, angles, as well as more complex or abstract features as we go deeper into the network. When designing a neural network, however, we do not explicitly make these filters perform these tasks, instead the network learns to do this on its own–given the goal or objective that we prescribe to the network–and often it is difficult to determine exactly what each filter is doing. This is the beauty of neural networks: by training the network without specifically engineering each component and each filter, the network learns how best to process the information. In the end, we see that they often reproduce certain tasks that the human visual pathways perform, likely because it is an optimal way to perform these tasks.
In the video, we took values found in the middle of the neural network, at a place called the latent space. Latent codes in this space are a way that the network represents certain faces, and from these codes we can build up the final image. We took a set of these values and interpolated between them to explore this latent space. Add on top of that some creepy music and we get “A.I. Nightmares.”
Links & References
Feng S, Wang X, Wang Q, Fang J, Wu Y, et al. (2018) The uncanny valley effect in typically developing children and its absence in children with autism spectrum disorders. PLOS ONE 13(11): e0206343.
Huang X, Liu MY, Belongie S, Kautz J. (2018) Multimodal Unsupervised Image-to-Image Translation. arXiv.org
Liu MY., Breuel T, Kautz J. (2017) Unsupervised Image-to-Image Translation Networks. arXiv.org
NVIDIA Labs GitHub Repository (2018) “MUNIT: Multimodal UNsupervised Image-to-image Translation”
Wikipedia Article: “Uncanny Valley”
StyleGAN Demo: “This Person Does Not Exist”